5G RAN Context
Before we start introducing specific concepts about Radio Access Network (RAN) deployments on OpenShift we first need to set the context around them:
-
Common configurations on almost any RAN deployment.
-
Linux features that are not commonly used outside RAN, but that are very important for RAN workloads.
-
Etc.
We won’t be covering these in many details, since that will require a lab of its own, we just need you to have basic knowledge on the topics being discussed.
Low Latency
RAN workloads usually require low latencies and deterministic behaviors, in Red Hat Enterprise Linux CoreOS we can make use of the real-time Kernel.
The real-time Kernel is not superior or better than the standard Kernel, instead it meets different business or system requirements.
This kernel is designed to maintain low latency, consistent response time, and determinism.
You can learn more about RT Kernel here.
NUMA Nodes
Historically, all memory on AMD64 and Intel64 systems was equally accessible by all CPUs, that is known as Uniform Memory Access (UMA). This behavior is no longer the case with recent AMD64 and Intel64 processors.
In Non-Uniform Memory Access (NUMA), system memory is divided across NUMA nodes, which correspond to sockets or to a particular set of CPUs that have identical access latency to the local subset of system memory.
There are three policies when memory needs to be allocated:
-
Strict: Memory allocation will fail if the memory cannot be allocated on the target NUMA node. -
Interleave: Memory is allocated across NUMA nodes in a round-robin fashion. -
Preferred: Memory will be allocated in the preferred NUMA node if there is room, otherwise will be allocated in another NUMA node.
Huge Pages
Physical memory is managed in fixed-size chunks called pages. On the x86_64 architecture, the default size of a memory page is 4 KB. This default page size has proved to be suitable for general-purpose operating systems which supports many kinds of workloads.
However, specific applications can benefit from using larger page sizes in certain cases. In order to reduce the overhead in the O.S and CPU we can pre-allocate memory pages with a larger fixed size that can later be consumed by our workloads.
You can learn more about huge pages in Linux here.
CPU Pinning
When running workloads in Linux these processes can be executed on any of multiple CPUs, the scheduler will assign CPUs to get the job done. While this may be good enough for general-purpose workloads, in latency sensitive environments that’s not usually the case. With CPU pinning we can restrict our workload to a given set of CPUs that will be dedicated to run our workload and nothing else, avoiding noisy neighbors and having access to the same compute power at any given time.
IRQ Load Balancing
Interrupt Requests (IRQ) need to be handled by the CPUs, in latency sensitive environments we want to limit the IRQs to a given set of CPUs in order to avoid taking compute power from workloads running on pinned CPUs for example. IRQs can be run on pinned CPUs unless otherwise specified.
DPDK
The Data Plane Development Kit (DPDK) is an open source software project that provides a set of data plane libraries and network interface controller polling-mode drivers for offloading TCP packet processing from the operating system kernel to processes running in user space.
DPDK libraries offer to free up the Kernel space from interrupts by processing the work in User space instead. This is possible thanks to the DPDK libraries and the DPDK poll mode driver (PMD). This driver is responsible for the communication between the application and network card, listening in a loop avoiding as much as possible interrupts while forwarding packets. The following diagram streamlines the idea:
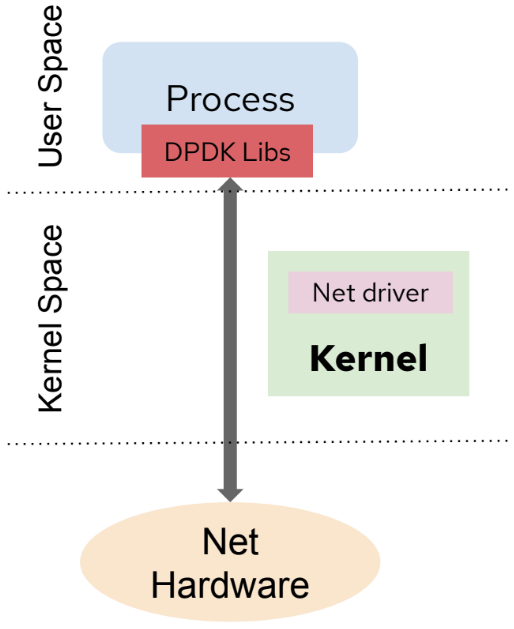
In OpenShift, it is possible to use the DPDK libraries and attach a network interface (SR-IOV virtual function) directly to the Pod. To ease the application building process, we can leverage Red Hat’s DPDK builder image available from Red Hat’s official registry. This base or builder image is intended to build applications powered by DPDK and also work with multiple CNI plugins.
Tuning for CPU Reduction
In RAN environments, on Single-Node OpenShift (SNO) the CPU usage by the platform must be reduced to the bare minimum so RAN workloads can benefit from as much CPU as possible. In order to accomplish that, the OpenShift platform will be limited to run their infrastructure components on a limited set of CPUs. This is what we call workload partitioning, the operating system (OS) and OCP components will be allowed to run only in a sub set of the available CPUs, leaving the rest of CPUs available for the RAN workloads.
On top of workload partitioning, the CNF team has tuned the OpenShift platform for RAN workloads by removing components that are not required in a RAN context such as Grafana Web Console, OpenShift Web Console, etc.
vRAN Dedicated Accelerators
Hardware accelerator cards accelerate 4G/LTE and 5G Virtualized Radio Access Networks (vRAN) workloads. This in turn increases the overall compute capacity of the platform.
vRAN accelerators are designed to offload and accelerate the computing-intensive process of forward error correction (FEC) for 4G/LTE and 5G technology, freeing up processing power.
As of OpenShift v4.12 the only accelerator supported is the Intel® vRAN Dedicated Accelerator ACC100, which can be managed through the use of an operator.
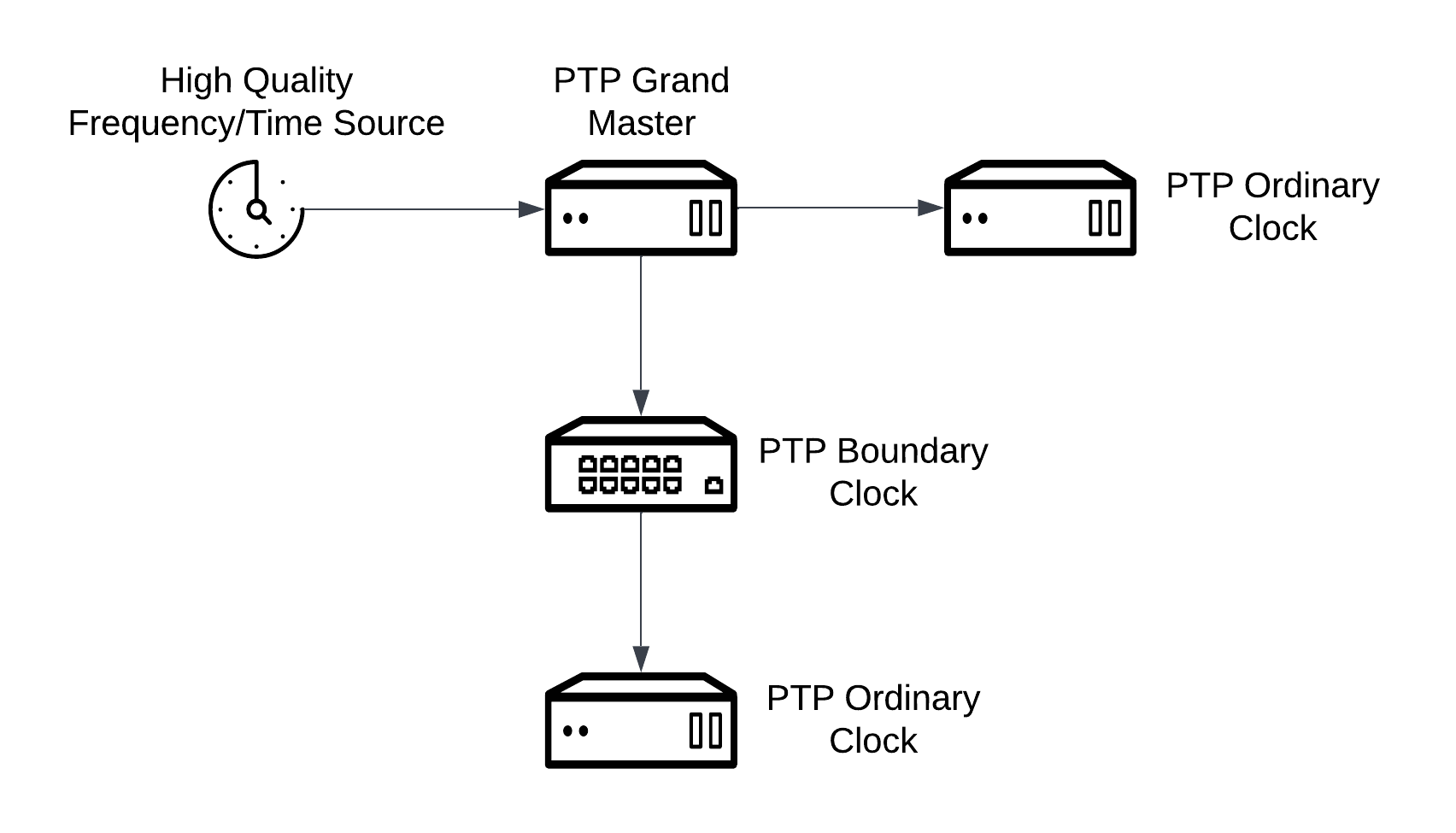
PTP
Precision Time Protocol (PTP) is used to synchronize clocks in a network. When used in conjunction with hardware support, PTP is capable of sub-microsecond accuracy, and is more accurate than Network Time Protocol (NTP).
PTP can work in three modes:
-
GrandMaster: A PTP daemon connected to a hardware with PTP support to synchronize its clock. Other PTP daemons will connect to this PTP GrandMaster in order to sync their clocks. -
Ordinary Clock: A PTP daemon connected to a GrandMaster to synchronize its clock. -
Boundary Clock: A PTP daemon connected to a GrandMaster to synchronize its clock and being master for other PTP daemons on the network.