Topology Aware Lifecycle Manager (TALM)
Leveraging TALM we can manage the lifecycle of thousands of clusters at scale in a constrained operational environment. This is required when working in telecom (eg RAN) or other environments where service level agreements require managed updates to a fleet of clusters.
Remember that ZTP generates installation and configuration resources from manifests (siteConfig and policyGenTemplates) stored in Git. These artifacts are applied to a centralized hub cluster where a combination of OpenShift GitOps, Red Hat Advanced Cluster Management, the Assisted Service deployed by the Infrastructure Operator, and the Topology Aware Lifecycle Manager (TALM) use them to install and configure the cluster. See ZTP components chapter.
TALM is responsible for managing the rollout of configuration throughout the lifecycle of the fleet of clusters. During initial deployment, the configuration phase of this ZTP process depends on TALM to orchestrate the application of the configuration custom resources to the cluster. When day-N configuration changes need to be rolled out to the fleet, TALM will manage that rollout in progressive limited size batches of clusters. When upgrades to OpenShift or the day-two operators are needed, TALM will progressively roll those out as well. There are several key integration points between GitOps, RHACM Policy, and TALM.
Default inform policies
In this solution, as mentioned in the Managing at scale section, all policies will be created with a remediation action of "inform". With this remediation action Red Hat ACM will notice the compliance state of the policy and raise the status to the user but will not take any action to apply the desired configuration. When the administrator of the fleet is ready to bring the clusters into compliance with the policy, TALM provides the tools and configurability to progressively remediate the fleet.
TALM will step through the set of created policies and switch them to an "enforce" policy in order to push configuration to the spoke cluster. This strategy ensures that initial deployment/ZTP integrates seamlessly with future configuration changes that need to be made without the risk of rolling those changes out to all spoke clusters in the network simultaneously.
| TALM enables us to select the timing and the clusters where the configuration is about to be applied. |
Cluster Group Upgrade (CGU)
The Topology Aware Lifecycle Manager (TALM) builds the remediation plan from the ClusterGroupUpgrade (CGU) custom resource for a group of clusters. You can define the following specifications in a ClusterGroupUpgrade CR. Note that this is a CGU CR that enforces an OpenShift release upgrade which was previously set by a policy called du-upgrade-platform-upgrade defined in the managedPolicies spec.
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
name: ocp-upgrade
namespace: ztp-group-du-sno
spec:
preCaching: true #precache enabled before upgrade
backup: true #backup enabled before upgrade
deleteObjectsOnCompletion: false
clusters: #Clusters in the group
- snonode-virt02
- snonode-virt01
- snonode-virt03
enable: true
managedPolicies:
- du-upgrade-platform-upgrade #Applicable list of managed policies
remediationStrategy:
canaries:
- snonode-virt01 #Defines the clusters for canary updates
maxConcurrency: 2 #Defines the maximum number of concurrent updates in a batch
timeout: 240| TALM does not only deal with OpenShift release upgrades, when we talk about upgrades in this section, we mean all kind of modifications to the managed clusters. Essentially, a CGU must be created everytime we want to enforce a policy. |
Auto creation of CGU
So far we have been talking of using TALM for our common day-2 operations. But, if a CGU must be created in order to enforce a previously applied policy, how is it possible to run a fully automated ZTP workflow, e.g. configure and even run our CNF workloads in a streamlined way, on the target clusters?
The answer is that TALM interacts with ZTP for newly created clusters. When we define one or multiple managed clusters in telco, we do not only want to provision them, we also want to apply a specific configuration such as the validated 5G RAN DU profile. Often, we also want our workloads run on top of them. ZTP is envisioned as a streamlined process, where as a developer we only push manifest definitions to the proper Git repository.
So, once clusters are provisioned, TALM monitors their state by checking the ManagedCluster CRs on the hub cluster. Any ManagedCluster CR which does not have a "ztp-done" label applied, including newly created ManagedCluster CRs, will cause TALM to automatically create a ClusterGroupUpgrade CR with the following characteristics:
-
It is created in the ztp-install namespace.
-
It has the same name as the ManagedCluster CR, usually the name of the cluster.
-
The cluster selector includes only the cluster associated with that ManagedCluster CR.
-
The set of managedPolicies includes ALL policies that RHACM has bound to the cluster at the time the CGU is created.
-
It is enabled.
-
Precaching is disabled.
-
Timeout set to 4 hours (240 minutes).
| TALM will basically enforce all existing policies that are bound to a cluster that has not the label "ztp-done'. This is performed by creating automatically a proper CGU CR. |
Phase labels
The ClusterGroupUpgrade CR that is auto created for ZTP includes directives to annotate the ManagedCluster CR with labels at the start and end of the ZTP process. When ZTP configuration (post-installation) commences, the ManagedCluster will have the ztp-running label applied. When all policies are remediated to the cluster (fully compliant) these directives will cause TALM to remove the ztp-running label and apply the ztp-done label.
In essence, the ztp-done label will be applied when the cluster is fully ready for deployment of applications.
Waves
A ZTP wave is basically an annotation (ran.openshift.io/ztp-deploy-wave) included on each policy template that will permit TALM to apply policies in an ordered manner. As an example, every policy generated from a PolicyGenTemplate by ZTP incorporates a wave number such as the SriovSubscriptionNS.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: openshift-sriov-network-operator
annotations:
workload.openshift.io/allowed: management
ran.openshift.io/ztp-deploy-wave: "2"| Detailed information on policy templates can be found in the following PolicyGen deepdive section. |
When TALM builds the auto-generated CGU as part of the ZTP phase, the included policies will be ordered according to these wave annotations. This is the only time that the wave annotations have any impact on TALM behavior.
As TALM works through the list of managedPolicies included in the CGU it will wait for each policy to be compliant before moving to the next policy. It is important to ensure that the order in which policies are listed under managedPolicies (and thus also the wave annotation used in populating this list during ZTP) takes into account any pre-requisites for the CRs in those policies to be applied to the cluster. For example an operator must be installed before, or concurrently with, the configuration for the operator.
| All CRs in the same policy must have the same setting for the ztp-deploy-wave annotation. The default value of this annotation for each CR can be overridden in the PolicyGenTemplate. Default ztp-deploy-wave value can be found on the proper source crs. |
Precaching
Clusters might have limited bandwidth to access the container image registry, which can cause a timeout before the updates are completed. This feature help us to schedule cluster upgrades to newer OCP releases in an organized manner and within the maintenance window assigned. Notice in the following picture, how the upgrade can be orchestrated depending on our requirements. See that prior to the maintenance window in which the upgrade will occur, TALM was configured to initiate pre-caching of all the artifacts needed for the upgrade. When the precaching status shows complete the actual upgrade can be enabled during a subsequent maintenance window.
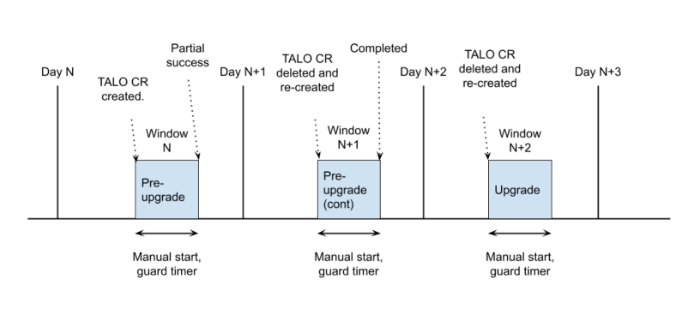
| Precaching currently only targets Single Node OpenShift clusters. |
By enabling precache feature without enabling the CGU, as shown in the following code snippet, the first thing is going to happen is pull all the container images required for the OCP release we are about to upgrade in the target cluster. So, we will have all required images already downloaded in our container-storage location, by default '/var/lib/containers', before even starting the upgrade task.
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
name: du-upgrade
namespace: ztp-group-du-sno
spec:
preCaching: true #precache configuration
backup: true
deleteObjectsOnCompletion: true
clusters:
- cnfdb1
- cnfdb2
enable: false #precache only
managedPolicies:
- du-upgrade-platform-upgrade
remediationStrategy:
maxConcurrency: 2
timeout: 240Once the container images are precached, we just need to enable the CGU by setting enabled: true. Then, a regular platform upgrade managed by the TALM operator will start. This time the update will be faster and resilient to transient network issues since the container images are stored locally.
| If both policy and precaching are enabled, the upgrade will be executed immediately after the precache is done successfully. |
A more in-detail explanation of the Precaching feature is covered in training material: "Precaching and sequential platform upgrades using TALM" recording.
Backup and Recovery
Backup & recovery feature creates a pre-upgrade backup and provides a procedure for rapid recovery of a SNO in the event of a failed upgrade. In such cases, this feature allows the SNO to be restored to a working state with the previous version of OCP without requiring a re-provision of the application(s).
| Backup & recovery currently only targets Single Node OpenShift clusters. |
Backup workload is a one-shot task created on each of the managed clusters to trigger backup and keep the backup and system resources in the recovery partition in order to recovery a failed upgrade. For SNO managed clusters it is realized as a batch/v1 job.
| It is highly recommended to create a recovery partition at install time if opted to use this feature. |
Below we can see the same CGU shown in the previous section, but this time the CGU is enabled. So, if the CGU and backup specs are enabled, then backup task is executed prior to the platform upgrade. If the backup finishes successfully, the upgrade task is started.
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
name: du-upgrade
namespace: ztp-group-du-sno
spec:
preCaching: true #precache was done
backup: true #backup feature enabled
deleteObjectsOnCompletion: true
clusters:
- cnfdb1
- cnfdb2
enable: true #backup is triggered when CGU is enabled
managedPolicies:
- du-upgrade-platform-upgrade
remediationStrategy:
maxConcurrency: 2
timeout: 240The backup workload generates a utility called upgrade-recovery.sh in the recovery partition or at the recovery folder at /var/recovery and takes the pre-upgrade backup. In addition, the active OS deployment is pinned using ostree and the standby deployments are removed.
In case, the upgrade failed in a managed cluster, the TALM CGU needs to be deleted in the hub cluster and an admin needs to log in to the spoke cluster to start the recovery process. The process is detailed in the Recovery from Upgrade failure documentation.
A more in-detail explanation of the Backup & Recovery is covered in this training material: "Upgrade, backup and recover your cluster with TALM" recording.