OpenShift GitOps
GitOps is a key part of how we deploy and manage RAN infrastructure at scale, in this section we are going to cover the basics around GitOps and how it is used in Zero Touch Provisioning (ZTP) and ongoing management of OpenShift clusters.
GitOps
GitOps brings proven patterns and methods of working from an IP operations workflow into management of OpenShift infrastructure. The desired state of the OpenShift infrastructure is captured within a Git repository where standard methods of change control, such as pull requests, reviews, sign-off, and merging, can be used to ensure changes are validated prior to taking effect. As with traditional source-code management, Git represents the single "source of truth" for the entire state of the system where the trail of changes to the system state are visible and auditable.
Traceability of changes in GitOps is no novelty in itself as this approach is almost universally employed for the application source code. However, GitOps advocates applying the same principles (reviews, pull requests, tagging, etc.) to infrastructure and application configuration so that teams can benefit from the same assurance as they do for the application source code.
Although there is no precise definition or agreed upon set of rules, the following principles are an approximation of what constitutes a GitOps practice:
-
Declarative description of the system is stored in Git (cluster definition, configuration, tuning, etc).
-
Changes to the state are made via pull requests and reviewed before merging.
-
Continuous integration reconciles "Git push" content in the Git repository with the state of the running system.
GitOps Principles
GitOps paradigm requires us to describe and observe systems with declarative specifications that eventually form the basis of continuous everything. (As a refresher, continuous everything includes but is not limited to continuous integration (CI), testing, delivery, deployment, analytics, governance with many more to come). By contrast, in an imperative paradigm, the user is responsible for defining exact steps which are necessary to achieve the end goal and carefully plan every step and the sequence in which they are executed.
GitOps achieves these tasks using declarative specifications stored in Git repositories, such as YAML files and other defined patterns, that provide a framework for deploying the infrastructure. The declarative output is leveraged by the Red Hat Advanced Cluster Management (RHACM) for multisite deployment.
| Red Hat OpenShift is a declarative Kubernetes platform that administrators can configure and manage using GitOps principles. Furthermore, Red Hat collaborates with open source projects like ArgoCD and Tekton to implement a framework for GitOps. |
One of the motivators for a GitOps approach is the requirement for reliability at scale. This is a significant challenge that GitOps helps solve. GitOps addresses the reliability issue by providing traceability, RBAC, and a single source of truth for the desired state of each site. Every change throughout the application life cycle is traced in the Git repository and is auditable. Making changes via Git means developers can finally do what they want: code at their own pace without waiting on resources to be assigned or approved by operations teams. Scale issues are addressed by GitOps providing structure, tooling, automation, and event driven operations through webhooks.
Below, the list of the basic principles on which GitOps stands:
-
The definition of our systems is described as code. The configuration for our systems can be treated as code, so we can store it and have it automatically versioned in Git, our single source of truth. That way we can deploy and update configuration of our systems in an easy way. Redeployment or hardware replacement is simply a (re)reconciliation of the configuration already captured in Git.
-
The desired system state and configuration is defined and versioned in Git. Having the desired configuration of our systems stored and versioned in Git give us the ability to roll out changes easily to our systems and applications. On top of that we can leverage Git’s security mechanisms in order to ensure the ownership and provenance of the code.
-
Changes to the configuration can be controlled using pull request (PR) mechanisms. Using Git Pull Requests we can ensure changes to cluster deployments and configuration are reviewed for correctness before taking effect. The originator of the change can request reviews from different team members, run CI tests/validation, etc. The changes become active only when the review is approved and the changes are merged to the main branch. RBAC configuration can be used to ensure that changes are made only by authorized users.
-
Changes to the configuration can be automatically applied using Continuous Integration. Using standard GitOps continuous integration infrastructure the desired state can be automatically applied to the set of managed clusters without needing to share your cluster credentials with anyone, the person committing the change only needs access to the Git repository where the configuration is stored. The continuous integration tools will recognize the change and automatically start the process of reconciling the changes.
-
There is a controller that ensures no configuration drifts are present. As the desired system state is present in Git, we only need a software that makes sure the current system state matches the desired system state. In case the states differ this software should be able to self-heal or notify the drift based on its configuration.
| Within the overall solution we have additional tools which ensure that the administrators of the clusters have the ability to control the timing of updates to clusters to ensure service level agreements aren’t violated. These tools and the way they intersect with GitOps will be discussed in later chapters. |
GitOps Patterns on OpenShift
By using the same Git-based workflows that developers are familiar with, GitOps expands upon existing processes from application development to deployment, application life cycle management, and infrastructure configuration. For ops teams, visibility to change means the ability to trace and reproduce issues quickly, improving overall security.
On-Cluster Resource Reconciler
In this pattern, a controller on the cluster is responsible for comparing the Kubernetes resources (YAML files) in the Git repository that acts as the single source of truth, with the resources on the cluster. When a discrepancy is detected, the controller would send out notifications and possibly take action to reconcile the resources on Kubernetes with the ones in the Git repository. Weaveworks Flux use this pattern in their GitOps implementation.
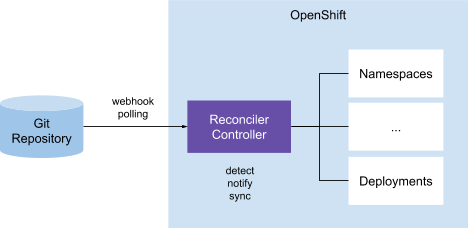
External Resource Reconciler (Push)
A variation of the previous pattern is that one or a number of controllers are responsible for keeping resources in sync between pairs of Git repositories and Kubernetes clusters. The difference with the previous pattern is that the controllers are not necessarily running on any of the managed clusters. The Git-k8s cluster pairs are often defined as a CRD which configures the controllers on how the sync should take place. The controllers in this pattern would compare the Git repository defined in the CRD with the resources on the Kubernetes cluster that is also defined in the CRD and takes action based on the result of the comparison. OpenShift GitOps based on ArgoCD is one of the solutions that uses this pattern for GitOps implementation.

| The GitOps ZTP methodology uses the OpenShift GitOps operator to synchronize Git to the RHACM hub cluster. |
Directories vs Branches
When using GitOps to manage infrastructure declaratively, the use of branches is an anti-pattern. We have been using branches for a long time when developing our applications, but when doing GitOps we are no longer developing an application, but defining a configuration. If we look at the different tooling around Kubernetes for managing configurations like Helm or Kustomize you will soon enough see that they know nothing about Git branches, they use just files. There are several reasons why organizing environments as directory structure in a single branch is preferred:
-
There is often configuration content which is common between environments. With a directory based structure this common configuration can be captured in a single place and referenced by the different environments. In a branch based model this content typically gets duplicated across the branches leading to drift.
-
In a directory model, clusters (or configuration content) can be moved between environments by a simple move rather than requiring a merge.
-
Comparing configuration between environments is simpler in a directory model.
-
Continuous deployment relies on subscriptions to the repository and branch which should be synchronized to the cluster(s). A branching model forces users to manage additional subscriptions per branch. In a directory model the user has options to use one subscription for multiple environments or multiple subscriptions.
One thing that we still need to keep in mind is that we want to have different repositories for the application code (where you can continue to use branches) and for the GitOps configuration.
Direct Commit to Main
Users can tailor their operational model to their particular use case, phase of operation, etc. Typically, a model where changes are directly committed to the main (active) branch is discouraged as this bypasses the merge review process and potentially exposes the clusters to incorrect/undesired changes. However, in some phases of operation such as initial development in the lab, a direct-commit to main model may be appropriate. GitOps allows for flexibility in the way users manage configuration in Git to suit their operational needs.
Pull Requests and Review Cycles
Once a user sends a pull request (PR) to a specific branch we should have some automated checks to make sure that the PR is safe, some of them could be:
-
Commits are signed by the user.
-
No passwords/confidential information is present in the PR.
-
Commit messages (logs) should have keywords that can be used to enforce some policies. For example putting the environment name and making sure the PR only changes files for that environment.
Once the automatic checks have passed, we want a different user to review the content of the PR and approve it once it’s ready.
| Review cycles for commits changing non-production environments can be automatic to reduce the time it takes for a change to hit the non-production environment. |
GitOps on OpenShift
The Red Hat OpenShift GitOps operator uses Argo CD to maintain cluster resources. Argo CD is an open-source declarative tool for the continuous integration and continuous deployment (CI/CD) of applications.
Some key features:
-
Ensure that the clusters have similar states for configuration, monitoring, and storage.
-
Apply or revert configuration changes to multiple OpenShift Container Platform clusters.
-
Associate templated configuration with different environments.
-
Promote applications across clusters, from staging to production.
You can learn more about OpenShift GitOps here.