Troubleshooting Tips
In this section, we will provide some useful tips to troubleshoot any issue that can arise during the execution of this lab.
| Below commands must be executed from the hypervisor host as root if not specified otherwise. |
Verification of the lab status
Git repository and registry
Both the registry and Git repository are running in the hypervisor host as containers:
podman psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e7cf765660a3 quay.io/mavazque/registry:2.7.1 /etc/docker/regis... 24 hours ago Up 24 hours ago registry
557b51f975ce quay.io/mavazque/gitea:1.17.3 /bin/s6-svscan /e... 24 hours ago Up 24 hours ago 0.0.0.0:2222->22/tcp, 0.0.0.0:3000->3000/tcp giteaSNO2 virtual machine
In the lab we are going to provision and configure a SNO cluster named SNO2. Let’s double check that the virtual machine exists and it is stopped.
kcli list vm+---------------+--------+----------------+------------------------------------------------------+-------------+---------+
| Name | Status | Ip | Source | Plan | Profile |
+---------------+--------+----------------+------------------------------------------------------+-------------+---------+
| hub-installer | up | 192.168.125.25 | CentOS-Stream-GenericCloud-8-20210603.0.x86_64.qcow2 | hub-cluster | kvirt |
| hub-master0 | up | 192.168.125.20 | | hub | kvirt |
| hub-master1 | up | 192.168.125.21 | | hub | kvirt |
| hub-master2 | up | 192.168.125.22 | | hub | kvirt |
| sno1 | up | 192.168.125.30 | | hub | kvirt |
| sno2 | down | | | hub | kvirt |
+---------------+--------+----------------+------------------------------------------------------+-------------+---------+Hub cluster
Before working with oc commands you can enable command auto-completion by running:
source <(oc completion bash)
# Make it persistent
oc completion bash >> /etc/bash_completion.d/oc_completionCheck the status of the hub cluster.
export KUBECONFIG=~/hub-kubeconfig
oc get clusterversionNAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.11.13 True False 22h Cluster version is 4.11.13oc get nodesNAME STATUS ROLES AGE VERSION
ocp-master-0 Ready master,worker 23h v1.24.6+5157800
ocp-master-1 Ready master,worker 23h v1.24.6+5157800
ocp-master-2 Ready master,worker 23h v1.24.6+5157800oc get operatorsNAME AGE
advanced-cluster-management.open-cluster-management 22h
multicluster-engine.multicluster-engine 22h
odf-lvm-operator.openshift-storage 22h
openshift-gitops-operator.openshift-operators 22h
topology-aware-lifecycle-manager.openshift-operators 22hoc get catalogsources -ANAMESPACE NAME DISPLAY TYPE PUBLISHER AGE
openshift-marketplace redhat-operator-index grpc 23hDNS resolution
Verify that the OpenShift API and the apps domain (wildcard) can be resolved.
dig command is not part of the standard linux utilities (you may need to install it), in RHEL-based systems is part of the bind-utils package.
|
dig +short api.hub.5g-deployment.lab192.168.125.10dig +short oauth-openshift.apps.hub.5g-deployment.lab192.168.125.11ArgoCD sync not working
There could be that one or both Argo applications (clusters or policies) are kept synchronizing or that their status is set to OutOfSync. In such cases we can double check the following:
First, check using oc binary the status of all the Argo applications. You can describe or show the full yaml definition of the failed application.
oc get applications -ANAMESPACE NAME SYNC STATUS HEALTH STATUS
openshift-gitops clusters OutOfSync Healthy
openshift-gitops hub-operators-config Synced Healthy
openshift-gitops hub-operators-deployment Synced Healthy
openshift-gitops policies Synced Healthy
openshift-gitops sno1-deployment Synced HealthyWe can also connect to the OpenShift GitOps console and see there the error. In this case, there is a missing value in the SiteConfig because we did not copy and paste it properly.
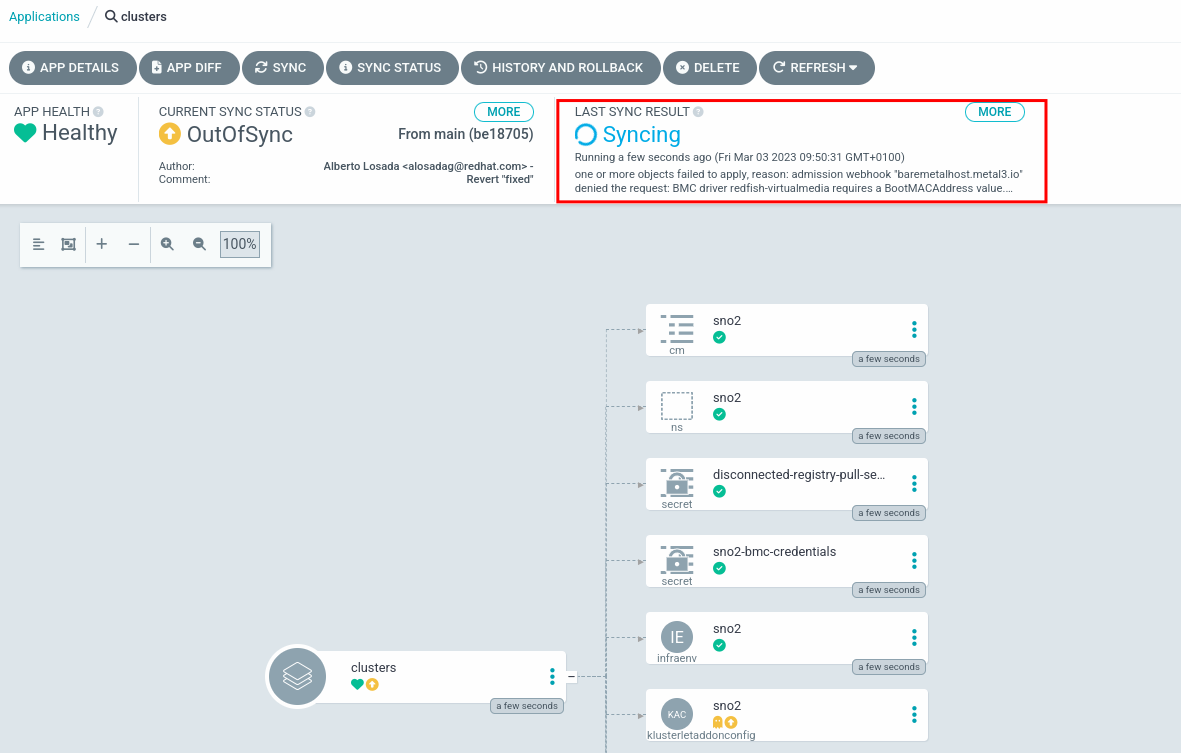
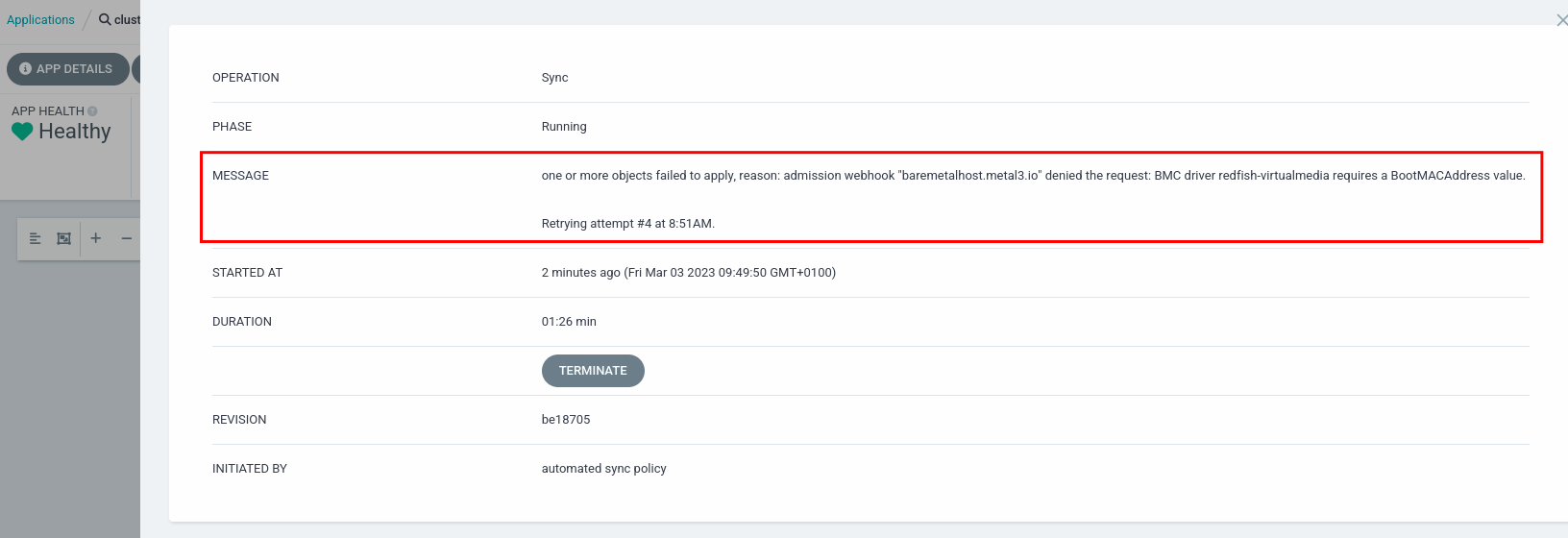
There are also cases that we need to synchronize manually the application because we modified the different manifests. For instance, as detailed in the previous example where we wrongly copy and paste the SiteConfig defnition. In those cases, we can workaround the issue by accessing the GitOps console using the local admin user and password.
This is the permission denied error shown in the console:
Execute this command connected to the hub cluster to obtain the local admin password. Then, logout and access again by typing admin as username and the password the one stored as a secret in the hub cluster:
oc extract secret/openshift-gitops-cluster -n openshift-gitops --to=-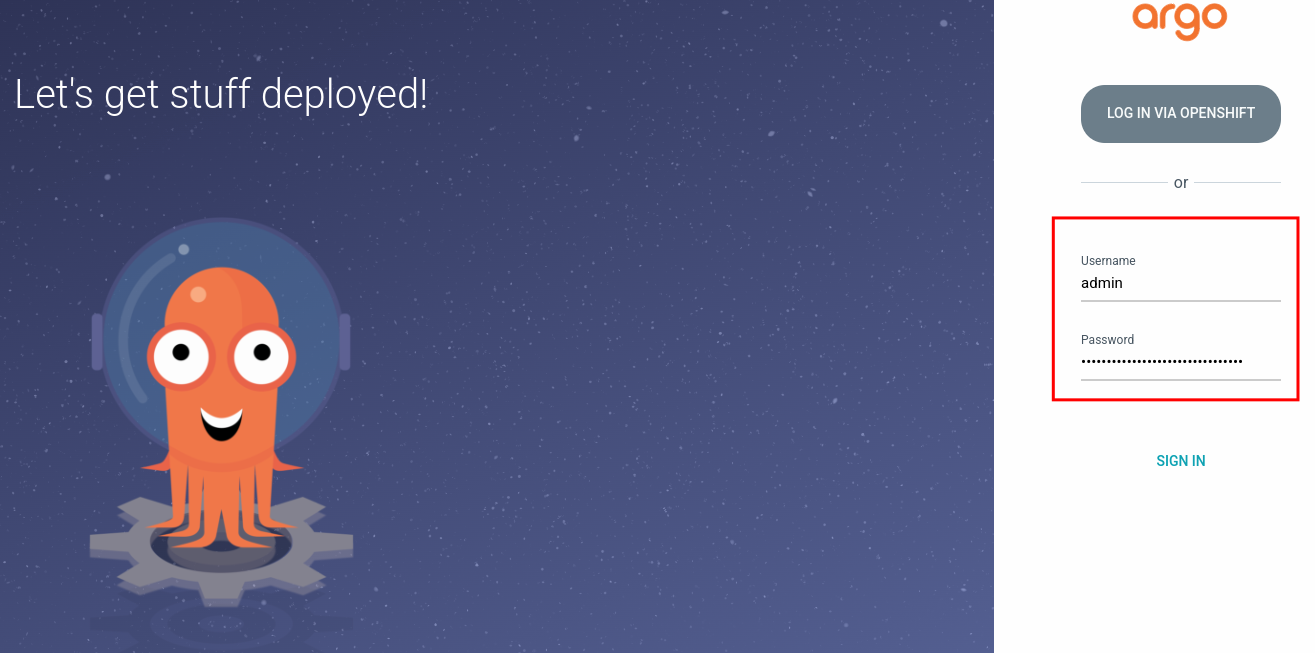
| More information about monitoring the status of the deployment can be found in the monitoring section. |
SNO2 is down after syncing Argo applications
So, we have synced the cluster and policies applications in Argo successfully, e.g. everything is in green. If after 5 minutes we do not see the SNO2 virtual machine being booted we can make use of the following troubleshooting commands:
First, check if the BMC is ready so the server can be started remotely from the hub using Redfish commands.
{
"@odata.type": "#ComputerSystem.v1_1_0.ComputerSystem",
"Id": "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0301",
"Name": "sno2",
"UUID": "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0301",
"Manufacturer": "Sushy Emulator",
"Status": {
"State": "Enabled",
"Health": "OK",
"HealthRollUp": "OK"
},
"PowerState": "Off",
... REDACTED ...
"@odata.context": "/redfish/v1/$metadata#ComputerSystem.ComputerSystem",
"@odata.id": "/redfish/v1/Systems/aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0301",
"@Redfish.Copyright": "Copyright 2014-2016 Distributed Management Task Force, Inc. (DMTF). For the full DMTF copyright policy, see http://www.dmtf.org/about/policies/copyright."If the server is up, but the installation is not progressing we may check a couple of things. First, let’s verify the sno2.5g-deployment.lab BaremetalHost CR is created and in provisioned status in the hub cluster.
oc get bmh -ANAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE
openshift-machine-api hub-ctlplane-0 externally provisioned hub-7tjlv-master-0 true 24h
openshift-machine-api hub-ctlplane-1 externally provisioned hub-7tjlv-master-1 true 24h
openshift-machine-api hub-ctlplane-2 externally provisioned hub-7tjlv-master-2 true 24h
sno1 sno1 provisioned true 24h
sno2 sno2.5g-deployment.lab provisioned true 112sVerify that the ISO image has been without errors by checking the InfraEnv and BaremetalHost custom resources:
oc get infraenv -ANAMESPACE NAME ISO CREATED AT
sno1 sno1 2023-03-01T10:08:09Z
sno2 sno2 2023-03-02T10:26:06Zoc get infraenv sno2 -n sno2 -oyamlapiVersion: agent-install.openshift.io/v1beta1
kind: InfraEnv
metadata:
... REDACTED ...
debugInfo:
eventsURL: https://assisted-service-multicluster-engine.apps.hub.5g-deployment.lab/api/assisted-install/v2/events?api_key=eyJhbGciOiJFUzI1NiIsInR5cCI6IkpXVCJ9.eyJpbmZyYV9lbnZfaWQiOiI2YWEzZGUxNS1hOTQ1LTRjNTgtODljOS02MDBkYzJmNWRmNTkifQ.fG3voLHggbgtCW9fQH1Y2vP5DSCOpo-t2pgDwvEe6Q7nE_Qp9-7BMKudpXiSTTYZCeWVE3s6nsAllP4IkK1ljA&infra_env_id=6aa3de15-a945-4c58-89c9-600dc2f5df59
isoDownloadURL: https://assisted-image-service-multicluster-engine.apps.hub.5g-deployment.lab/images/6aa3de15-a945-4c58-89c9-600dc2f5df59?api_key=eyJhbGciOiJFUzI1NiIsInR5cCI6IkpXVCJ9.eyJpbmZyYV9lbnZfaWQiOiI2YWEzZGUxNS1hOTQ1LTRjNTgtODljOS02MDBkYzJmNWRmNTkifQ.AFhkv4UPH0R0kGpBdZ8cqo8iNSH7z-CRsHsYbwQ6cVzjcnxnDRIEiout29UJOyt-lcCPPsOLW1YPKDh5GJ1Tqg&arch=x86_64&type=minimal-iso&version=4.11oc get bmh sno2.5g-deployment.lab -n sno2 -o yamlapiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
... REDACTED ...
image:
format: live-iso
url: https://assisted-image-service-multicluster-engine.apps.hub.5g-deployment.lab/images/6aa3de15-a945-4c58-89c9-600dc2f5df59?api_key=eyJhbGciOiJFUzI1NiIsInR5cCI6IkpXVCJ9.eyJpbmZyYV9lbnZfaWQiOiI2YWEzZGUxNS1hOTQ1LTRjNTgtODljOS02MDBkYzJmNWRmNTkifQ.AFhkv4UPH0R0kGpBdZ8cqo8iNSH7z-CRsHsYbwQ6cVzjcnxnDRIEiout29UJOyt-lcCPPsOLW1YPKDh5GJ1Tqg&arch=x86_64&type=minimal-iso&version=4.11
online: true| More information about monitoring the status of the deployment can be found in the monitoring section. |
Policies not showing in the Governance console
In cases where the policies are not shown in the Governance section of the Multicloud console we have to check first, if the policies Argo application was synced successfully. If not, repeat the steps detailed in the previous section
Verfiy that the policies in the hub cluster are similar to the ones shown below. Remember that inform as remediation is correct.
oc get policies -ANAMESPACE NAME REMEDIATION ACTION COMPLIANCE STATE AGE
sno2 ztp-policies.common-operator-catalog-411 inform 14m
sno2 ztp-policies.group-du-sno-du-profile-wave1 inform 14m
sno2 ztp-policies.group-du-sno-du-profile-wave10 inform 14m
sno2 ztp-policies.site-sno2-performance-policy inform 14m
sno2 ztp-policies.site-sno2-storage-configuration inform 14m
sno2 ztp-policies.site-sno2-tuned-policy inform 14m
sno2 ztp-policies.zone-europe-storage-operator inform 14m
ztp-policies common-operator-catalog-411 inform 35m
ztp-policies group-du-sno-du-profile-wave1 inform 35m
ztp-policies group-du-sno-du-profile-wave10 inform 35m
ztp-policies site-sno2-performance-policy inform 35m
ztp-policies site-sno2-storage-configuration inform 35m
ztp-policies site-sno2-tuned-policy inform 35m
ztp-policies zone-europe-storage-operator inform 35mPolicies not applied
In such cases it can be because of multiple errors. First, let’s check that the policies are shown in the Governance console.
If the policies show a warning message in the Cluster violations section, it is because the SNO2 server is still being provisioned. You can double check the status of the provisioning in the Infrastructure → Clusters section. Verify that there is not ztp-running label added yet.
In cases where the Governance console shows policies already assigned to SNO2, we should check the status of the TALM operator. Remember, that it is responsible of moving the policies from inform to enforce, so they are eventually applied. Check the status of the cluster-group-upgrades-controller-manager Pod and its logs:
oc get pods -n openshift-operatorsNAME READY STATUS RESTARTS AGE
cluster-group-upgrades-controller-manager-b757bcdb9-46xtx 2/2 Running 1 (24h ago) 24h
gitops-operator-controller-manager-cd79b49dc-tvdp6 1/1 Running 0 25hNext, we can verify that a ClusterGroupUpgrade CR was created automatically by the TALM operator. If it is not created, it means that either the label is not set yet in the cluster or the operator is having issues. In the latest case, check the logs as explained previously.
oc get cgu -ANAMESPACE NAME UPGRADE STATE AGE
ztp-install sno2 UpgradeNotCompleted 2m27sDescribing the CGU shows a lot of information about the current status of the configuration:
oc get cgu -n ztp-install sno2 -oyamlapiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
... REDACTED ...
status:
computedMaxConcurrency: 1
conditions:
- lastTransitionTime: "2023-03-02T11:16:09Z"
message: The ClusterGroupUpgrade CR has upgrade policies that are still non compliant
reason: UpgradeNotCompleted
status: "False"
type: Ready
copiedPolicies:
- sno2-common-operator-catalog-411-2rtdv
- sno2-group-du-sno-du-profile-wave1-4jrqr
- sno2-group-du-sno-du-profile-wave10-xbbsz
- sno2-site-sno2-performance-policy-gbpns
- sno2-site-sno2-storage-configuration-7wwv4
- sno2-site-sno2-tuned-policy-969jx
- sno2-zone-europe-storage-operator-q2bfh
... REDACTED ...
currentBatch: 1
currentBatchRemediationProgress:
sno2:
policyIndex: 2
state: InProgress
currentBatchStartedAt: "2023-03-02T11:16:09Z"
startedAt: "2023-03-02T11:16:09Z"Verfiy that now there are two times the number of policies in the hub cluster. That’s because a enforce copy of each one of them was created.
oc get policies -ANAMESPACE NAME REMEDIATION ACTION COMPLIANCE STATE AGE
sno2 ztp-install.sno2-common-operator-catalog-411-2rtdv enforce Compliant 6m8s
sno2 ztp-install.sno2-group-du-sno-du-profile-wave1-4jrqr enforce Compliant 5m17s
sno2 ztp-install.sno2-group-du-sno-du-profile-wave10-xbbsz enforce Compliant 2m38s
sno2 ztp-install.sno2-site-sno2-performance-policy-gbpns enforce NonCompliant 68s
sno2 ztp-install.sno2-zone-europe-storage-operator-q2bfh enforce Compliant 4m59s
sno2 ztp-policies.common-operator-catalog-411 inform Compliant 56m
sno2 ztp-policies.group-du-sno-du-profile-wave1 inform Compliant 56m
sno2 ztp-policies.group-du-sno-du-profile-wave10 inform Compliant 56m
sno2 ztp-policies.site-sno2-performance-policy inform NonCompliant 56m
sno2 ztp-policies.site-sno2-storage-configuration inform NonCompliant 56m
sno2 ztp-policies.site-sno2-tuned-policy inform NonCompliant 56m
sno2 ztp-policies.zone-europe-storage-operator inform Compliant 56m
ztp-install sno2-common-operator-catalog-411-2rtdv enforce Compliant 6m8s
ztp-install sno2-group-du-sno-du-profile-wave1-4jrqr enforce Compliant 6m8s
ztp-install sno2-group-du-sno-du-profile-wave10-xbbsz enforce Compliant 6m8s
ztp-install sno2-site-sno2-performance-policy-gbpns enforce NonCompliant 6m8s
ztp-install sno2-site-sno2-storage-configuration-7wwv4 enforce 6m8s
ztp-install sno2-site-sno2-tuned-policy-969jx enforce 6m8s
ztp-install sno2-zone-europe-storage-operator-q2bfh enforce Compliant 6m8s
ztp-policies common-operator-catalog-411 inform Compliant 77m
ztp-policies group-du-sno-du-profile-wave1 inform Compliant 77m
ztp-policies group-du-sno-du-profile-wave10 inform Compliant 77m
ztp-policies site-sno2-performance-policy inform NonCompliant 77m
ztp-policies site-sno2-storage-configuration inform NonCompliant 77m
ztp-policies site-sno2-tuned-policy inform NonCompliant 77m
ztp-policies zone-europe-storage-operator inform Compliant 77m| Each enforce policy is being applied one by one. There can be cases where the Cluster violations or the Compliance status is not set for the enforced cluster. It takes time to move to the next one depending on the changes applied to the target cluster. |
OLM Bug
If the SNO cluster policies are not moving to Compliant after a while, you may be hitting this bug.
You need to check the subscriptions status on the SNO clusters, in order to do that you need to get the kubeconfigs:
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig -n sno1 extract secret/sno1-admin-kubeconfig --to=- > ~/5g-deployment-lab/sno1-kubeconfig
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig -n sno2 extract secret/sno2-admin-kubeconfig --to=- > ~/5g-deployment-lab/sno2-kubeconfigProbably your subscriptions are stuck and are showing a message like the one below:
| Command below checks sno2, you may want to check the SNO where policies are stuck. |
oc --kubeconfig ~/5g-deployment-lab/sno2-kubeconfig -n openshift-storage get subscriptions.operators.coreos.com odf-lvm-operator -o yamlapiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
creationTimestamp: "2023-06-14T14:35:17Z"
generation: 1
labels:
operators.coreos.com/lvms-operator.openshift-storage: ""
test: test
name: odf-lvm-operator
namespace: openshift-storage
resourceVersion: "70835"
uid: f30a26a2-fdaf-4469-8271-d5d5ac0cb64c
spec:
channel: stable-4.12
installPlanApproval: Manual
name: lvms-operator
source: redhat-operator-index
sourceNamespace: openshift-marketplace
status:
catalogHealth:
- catalogSourceRef:
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
name: redhat-operator-index
namespace: openshift-marketplace
resourceVersion: "70778"
uid: e9ebbd29-f28d-4619-ab71-66bed8e52de2
healthy: true
lastUpdated: "2023-06-14T15:34:53Z"
conditions:
- lastTransitionTime: "2023-06-14T15:34:53Z"
message: all available catalogsources are healthy
reason: AllCatalogSourcesHealthy
status: "False"
type: CatalogSourcesUnhealthy
- message: 'failed to populate resolver cache from source community-operators/openshift-marketplace:
failed to list bundles: rpc error: code = Unavailable desc = connection error:
desc = "transport: Error while dialing dial tcp: lookup community-operators.openshift-marketplace.svc
on 172.30.0.10:53: no such host"'
reason: ErrorPreventedResolution
status: "True"
type: ResolutionFailedIf that’s the case you should restart OLM pods to get this fixed:
oc --kubeconfig ~/5g-deployment-lab/sno1-kubeconfig -n openshift-operator-lifecycle-manager delete pods --allOnce OLM is restarted the subscriptions will move to the desired stated.