Using TALM to Update Clusters
In this section, we will perform a platform upgrade to both managed clusters using the pre-cache and backup feature implemented in the Topology Aware Lifecycle Manager (TALM) operator. The pre-cache feature prepares the maintenance operation in the managed clusters by pulling the required artifacts prior to the upgrade. The reasoning behind this feature is that SNO spoke clusters may have limited bandwidth to the container registry, which will make it difficult for the upgrade to complete within the required time. In order to ensure the upgrade can fit within the maintenance window, the required artifacts need to be present on the spoke cluster prior to the upgrade. The idea is pre-caching all the images needed for the platform and operator upgrade on the node, so they are not pulled at upgrade time. Do it in a maintenance window(s) before the upgrade maintenance window.
The backup feature, on the other hand, implements a procedure for rapid recovery of a SNO in the event of a failed upgrade that is unrecoverable. The SNO needs to be restored to a working state with the previous version of OCP without requiring a re-provision of the application(s).
| The backup feature only allows SNOs to be restored, this is not applicable to any other kind of OpenShift clusters. |
Let’s upgrade our both clusters. First of all, let’s verify the TALM operator is running in our hub cluster:
Verifying the TALM state
| Below commands must be executed from the workstation host if not specified otherwise. |
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get operatorsNAME AGE
advanced-cluster-management.open-cluster-management 16h
lvms-operator.openshift-storage 16h
multicluster-engine.multicluster-engine 16h
openshift-gitops-operator.openshift-operators 16h
topology-aware-lifecycle-manager.openshift-operators 16hNext, double check there is no problem with the Pod. Notice that the name of the Pod is cluster-group-upgrade-controller-manager, based on the name of the upstream project Cluster Group Upgrade Operator.
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get pods,sa,deployments -n openshift-operatorsNAME READY STATUS RESTARTS AGE
pod/cluster-group-upgrades-controller-manager-6d6fc98d-6cnf9 2/2 Running 1 (2d14h ago) 2d14h
pod/gitops-operator-controller-manager-c6bc6db9f-5z752 1/1 Running 0 2d15h
NAME SECRETS AGE
serviceaccount/builder 1 2d16h
serviceaccount/cluster-group-upgrades-controller-manager 1 2d14h
serviceaccount/cluster-group-upgrades-operator-controller-manager 1 2d14h
serviceaccount/default 1 2d16h
serviceaccount/deployer 1 2d16h
serviceaccount/gitops-operator-controller-manager 1 2d15h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/cluster-group-upgrades-controller-manager 1/1 1 1 2d14h
deployment.apps/gitops-operator-controller-manager 1/1 1 1 2d15hFinally, let’s take a look at the cluster group upgrade (CGU) CRD managed by TALM. If we pay a closer look we will notice that an already completed CGU was applied to SNO2. As we mentioned in inform policies section, all policies are not enforced, the user has to create the proper CGU resource to enforce them. However, when using ZTP, we want our cluster provisioned and configured automatically. This is where TALM will step through the set of created policies (inform) and will enforce them once the cluster was successfully provisioned. Therefore, the configuration stage starts without any intervention ending up with our OpenShift cluster ready to process workloads.
It’s possible that you get UpgradeNotCompleted, if that’s the case you need to wait for the remaining policies to be applied. You can check policies status here.
|
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get cgu -ANAMESPACE NAME AGE STATE DETAILS
ztp-install sno2 3h29m Completed All clusters are compliant with all the managed policiesGetting the SNO clusters kubeconfigs
In the previous sections we have deployed the sno2 cluster and attached the sno1 cluster. Before we continue with TALM, let’s grab the kubeconfigs for both cluster since we will need them for the next sections.
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig -n sno1 extract secret/sno1-admin-kubeconfig --to=- > ~/5g-deployment-lab/sno1-kubeconfig
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig -n sno2 extract secret/sno2-admin-kubeconfig --to=- > ~/5g-deployment-lab/sno2-kubeconfigCreating the upgrade PGT
Create an upgrade PGT in inform mode, as usual, that will apply and upgrade the SNOs located in Europe (binding rule: du-zone: "europe"), SNO1 and SNO2 clusters. This file needs to be created in the ztp-repository Git repo that we have created.
cat <<EOF > ~/5g-deployment-lab/ztp-repository/site-policies/fleet/active/zone-europe-upgrade-412-5.yaml
---
apiVersion: ran.openshift.io/v1
kind: PolicyGenTemplate
metadata:
name: "europe-snos-upgrade"
namespace: "ztp-policies"
spec:
bindingRules:
du-zone: "europe"
logicalGroup: "active"
mcp: "master"
remediationAction: inform
sourceFiles:
- fileName: ClusterVersion.yaml
policyName: "version-412-5"
metadata:
name: version
spec:
channel: "stable-4.12"
desiredUpdate:
force: false
version: "4.12.5"
image: "infra.5g-deployment.lab:8443/openshift/release-images@sha256:fd65cebce150bac3c622e30e7f762d3173575ae3541b3a7648819cb63e9b63a4"
status:
history:
- version: "4.12.5"
state: "Completed"
EOFModify the kustomization.yaml inside the site-policies folder, so it includes this new PGT and eventually will be applied by ArgoCD.
sed -i "/- group-du-sno.yaml/a \ \ - zone-europe-upgrade-412-5.yaml" ~/5g-deployment-lab/ztp-repository/site-policies/fleet/active/kustomization.yamlThen commit all the changes:
cd ~/5g-deployment-lab/ztp-repository/
git add site-policies/fleet/active/zone-europe-upgrade-412-5.yaml site-policies/fleet/active/kustomization.yaml
git commit -m "adds upgrade policy"
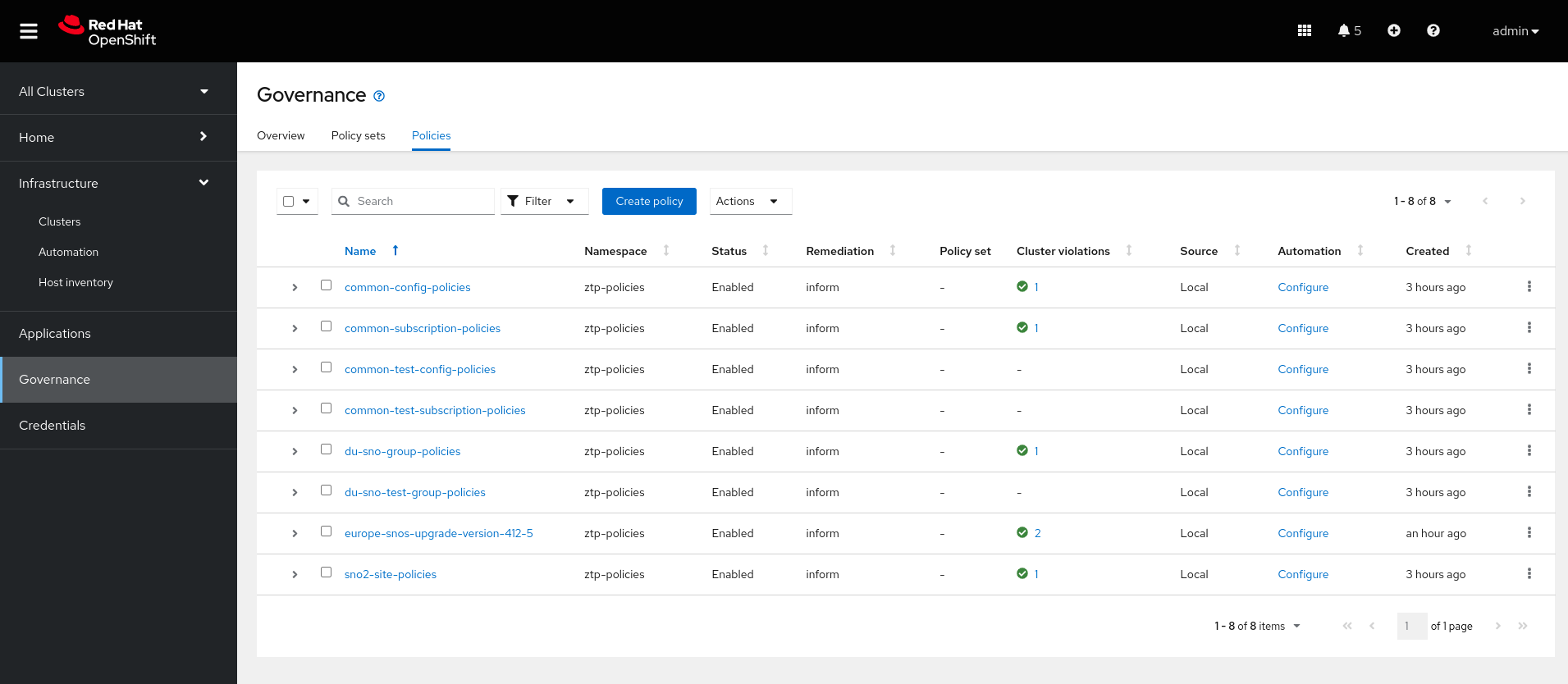
git push origin mainOnce committed, in a couple of minutes we will see a new policy in the multicloud RHACM console. As noticed, the policy named europe-snos-upgrade-version-412-5 has a violation. However, only one cluster is not compliant. If we check the policy information we will see that this policy is only targeting SNO2 cluster. That’s because the SNO1 cluster does not have the labels zone-europe and active logicalGroup that the PGT is targeting in its binding rule.
| Notice in the following picture that there are policies not applying to any cluster. Those are policies targeting the test environment. This is expected since we do not have any clusters in the test environment, e.g, no clusters are labeled with the proper label for testing: logicalGroup=test. |
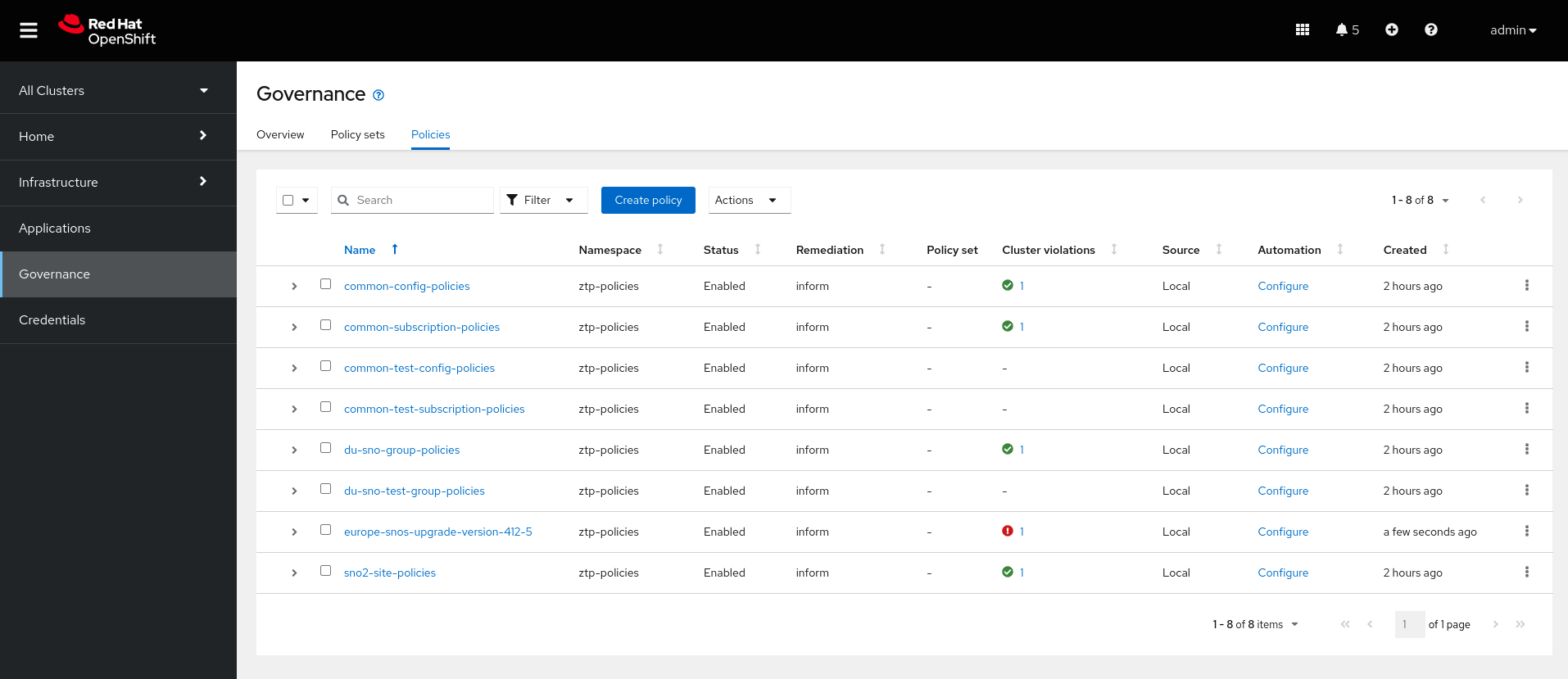
Let’s add the proper labels to the production cluster SNO1:
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig label managedcluster sno1 du-zone=europe logicalGroup=activemanagedcluster.cluster.open-cluster-management.io/sno1 labeledApplying the upgrade
At this point, we need to create a Cluster Group Upgrade (CGU) resource that will start the upgrade process. In our case, the process will be divided into two stages:
-
Run a pre-cache of the new OCP release prior to start the upgrade process.
-
Before running the upgrade, a backup will be done.
Backup and pre-cache
Let’s create the CGU. In this case, we will apply the managed policy (europe-snos-upgrade-version-412-5) to both clusters at the same time (maxConcurrency is 2). Notice that the CGU is disabled, this is suggested if we are going to run the precaching feature. This means, that once the precaching process is done we are ready to start the upgrade process by enabling the CGU. This idea is related to the compliance of a maintenance window in an enterprise.
Remember that several gigabytes of artifacts needs to be downloaded to the spoke for a full upgrade. SNO spoke clusters may have limited bandwidth to the hub cluster hosting the registry, which will make it difficult for the upgrade to complete within the required time. In order to ensure the upgrade can fit within the maintenance window, the required artifacts need to be present on the spoke cluster prior to the upgrade. Therefore, the process is split up into two stages as mentioned.
Let’s apply the CGU to our hub cluster:
cat <<EOF | oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig apply -f -
---
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
name: update-europe-snos
namespace: ztp-policies
spec:
preCaching: true
backup: true
clusters:
- sno1
- sno2
enable: false
managedPolicies:
- europe-snos-upgrade-version-412-5
remediationStrategy:
maxConcurrency: 2
timeout: 240
EOFOnce applied, we can see that the status moved to PrecacheSpecIsWellFormed. This means that the first step in our process is executing the pre-cache.
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get cgu -ANAMESPACE NAME AGE STATE DETAILS
ztp-install sno2 3h40m Completed All clusters are compliant with all the managed policies
ztp-policies update-europe-snos 10s PrecacheSpecIsWellFormed Precaching spec is valid and consistentConnecting to any of our spoke clusters we can see a new job being created called pre-cache.
| Notice that pre-cache job can take up to 5m to be created. |
oc --kubeconfig ~/5g-deployment-lab/sno2-kubeconfig -n openshift-talo-pre-cache get job pre-cacheNAME COMPLETIONS DURATION AGE
pre-cache 0/1 64s 64sThis job creates a Pod that will run the precache process. As we can see below, 183 images need to be downloaded from our local registry to mark the task as successful.
oc --kubeconfig ~/5g-deployment-lab/sno2-kubeconfig logs job/pre-cache -n openshift-talo-pre-cache -fupgrades.pre-cache 2023-03-16T12:59:10+00:00 DEBUG Release index image processing done
58ff6e48f95bf6b444150290f481ad6fc6051e76defccf3611bdc2f9ddc1cccc
upgrades.pre-cache 2023-03-16T12:59:10+00:00 DEBUG Operators index is not specified. Operators will not be pre-cached
upgrades.pre-cache 2023-03-16T12:59:10+00:00 DEBUG Pulling quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:006e37a1f141eb219364a501767fb4a26210908385eef9576af00b55d8225ecb [1/183]
upgrades.pre-cache 2023-03-16T12:59:10+00:00 DEBUG Pulling quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:01b510f238c0a8ad44df44d4aba3d0d2cfa429153ce3f451095484815f5746fd [2/183]
upgrades.pre-cache 2023-03-16T12:59:11+00:00 DEBUG Pulling quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:02c9c2a2ef5941156a767d40abe900a669a8237a8444a3974b360c326a21ffc3 [3/183]
.
.
.
upgrades.pre-cache 2023-03-16T13:13:37+00:00 DEBUG Pulling quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:fe86e187b2664371923282d88426a183ccddc75305d9ee5b6e64a082d179b596 [182/183]
upgrades.pre-cache 2023-03-16T13:13:48+00:00 DEBUG Pulling quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:fec91120672f68e7671b6f1fc17becf5aee9c72e540e046874a216d68bd04ffc [183/183]
upgrades.pre-cache 2023-03-16T13:13:48+00:00 DEBUG Image pre-cache doneOnce the precache is done, the CGU state moves to NotEnabled. At this moment, TALM is waiting for acknowledging the start of the upgrade.
| It can take up to 5 minutes for the CGU to report the new state. |
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get cgu -ANAMESPACE NAME AGE STATE DETAILS
ztp-install sno2 4h Completed All clusters are compliant with all the managed policies
ztp-policies update-europe-snos 20m NotEnabled Not enabledTriggering the upgrade
Now that the pre-cache is done, we can trigger the update. As we said earlier, before the update is actually executed a backup will be done so we can rollback. In order to trigger the update we need to enable the CGU:
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig patch cgu update-europe-snos -n ztp-policies --type merge --patch '{"spec":{"enable":true}}'Notice the CGU state moved to InProgress, which means, the upgrade process has started. In the details you can see that the backup is in progress.
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get cgu -ANAMESPACE NAME AGE STATE DETAILS
ztp-install sno2 4h6m Completed All clusters are compliant with all the managed policies
ztp-policies update-europe-snos 25m InProgress Backup in progress for 2 clustersConnecting to any of our spoke clusters we can see a new job being created called backup-agent.
| Notice that backup job can take up to 5m to be created. |
oc --kubeconfig ~/5g-deployment-lab/sno1-kubeconfig get jobs -ANAMESPACE NAME COMPLETIONS DURATION AGE
assisted-installer assisted-installer-controller 1/1 38m 4h47m
openshift-marketplace 51f5147f46ba2fcbd47cc8cba3f7a6f28f7cc23b267e380ac5a1ee1de87d962 1/1 11s 4h2m
openshift-operator-lifecycle-manager collect-profiles-27982845 1/1 7s 39m
openshift-operator-lifecycle-manager collect-profiles-27982860 1/1 118s 24m
openshift-operator-lifecycle-manager collect-profiles-27982875 1/1 7s 9m2s
openshift-talo-backup backup-agent 0/1 30s 30s
openshift-talo-pre-cache pre-cache 1/1 16m 25mThis job basically runs a Pod that will execute a recovery procedure and will store all required data into the /var/recovery folder of each spoke.
oc --kubeconfig ~/5g-deployment-lab/sno2-kubeconfig logs job/backup-agent -n openshift-talo-backup -fINFO[0000] ------------------------------------------------------------
INFO[0000] Cleaning up old content...
INFO[0000] ------------------------------------------------------------
INFO[0000] Old directories deleted with contents
INFO[0000] Old contents have been cleaned up
INFO[0004] Available disk space : 155.49 GiB; Estimated disk space required for backup: 340.63 MiB
INFO[0004] Sufficient disk space found to trigger backup
INFO[0004] Upgrade recovery script written
INFO[0004] Running: bash -c /var/recovery/upgrade-recovery.sh --take-backup --dir /var/recovery
INFO[0004] ##### Thu Mar 16 13:24:20 UTC 2023: Taking backup
INFO[0004] ##### Thu Mar 16 13:24:20 UTC 2023: Wiping previous deployments and pinning active
INFO[0005] error: Out of range deployment index 1, expected < 1
INFO[0005] Deployment 0 is now pinned
INFO[0005] ##### Thu Mar 16 13:24:21 UTC 2023: Backing up container cluster and required files
INFO[0005] Certificate /etc/kubernetes/static-pod-certs/configmaps/etcd-serving-ca/ca-bundle.crt is missing. Checking in different directory
INFO[0005] Certificate /etc/kubernetes/static-pod-resources/etcd-certs/configmaps/etcd-serving-ca/ca-bundle.crt found!
INFO[0006] found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6
INFO[0006] found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-9
INFO[0006] found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-8
INFO[0007] found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3
INFO[0009] 519d313c23c0fea1d1aed4366dd935663680a6a253bbb254ae7071ff3c66899c
INFO[0009] etcdctl version: 3.5.6
INFO[0009] API version: 3.5
INFO[0009] {"level":"info","ts":"2023-03-16T13:24:26.056Z","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/var/recovery/cluster/snapshot_2023-03-16_132422.db.part"}
INFO[0009] {"level":"info","ts":"2023-03-16T13:24:26.068Z","logger":"client","caller":"v3@v3.5.6/maintenance.go:212","msg":"opened snapshot stream; downloading"}
INFO[0009] {"level":"info","ts":"2023-03-16T13:24:26.068Z","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"https://192.168.125.40:2379"}
INFO[0010] {"level":"info","ts":"2023-03-16T13:24:26.991Z","logger":"client","caller":"v3@v3.5.6/maintenance.go:220","msg":"completed snapshot read; closing"}
INFO[0011] {"level":"info","ts":"2023-03-16T13:24:27.355Z","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"https://192.168.125.40:2379","size":"92 MB","took":"1 second ago"}
INFO[0011] {"level":"info","ts":"2023-03-16T13:24:27.355Z","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/var/recovery/cluster/snapshot_2023-03-16_132422.db"}
INFO[0011] Snapshot saved at /var/recovery/cluster/snapshot_2023-03-16_132422.db
INFO[0011] Deprecated: Use `etcdutl snapshot status` instead.
INFO[0011]
INFO[0011] {"hash":1194329918,"revision":85030,"totalKey":7098,"totalSize":91566080}
INFO[0011] snapshot db and kube resources are successfully saved to /var/recovery/cluster
INFO[0018] Command succeeded: rsync -a /etc/ /var/recovery/etc/
INFO[0019] Command succeeded: rsync -a /usr/local/ /var/recovery/usrlocal/
INFO[0023] Command succeeded: rsync -a /var/lib/kubelet/ /var/recovery/kubelet/
INFO[0023] ##### Thu Mar 16 13:24:40 UTC 2023: Backup complete
INFO[0023] ------------------------------------------------------------
INFO[0023] backup has successfully finished ...Once backups are finished for all clusters, the CGU state will move to BackupCompleted:
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get cgu -ANAMESPACE NAME AGE STATE DETAILS
ztp-install sno2 4h9m Completed All clusters are compliant with all the managed policies
ztp-policies update-europe-snos 28m BackupCompleted Backup is completed for all clustersAt this point, if we connect to any of our spoke clusters we can see that the upgrade process is actually taking place.
oc --kubeconfig ~/5g-deployment-lab/sno2-kubeconfig get clusterversion,nodesNAME VERSION AVAILABLE PROGRESSING SINCE STATUS
clusterversion.config.openshift.io/version 4.12.3 True True 4m2s Working towards 4.12.5: 213 of 829 done (25% complete), waiting on config-operator, machine-api
NAME STATUS ROLES AGE VERSION
node/sno2.5g-deployment.lab Ready control-plane,master,worker 5h7m v1.25.4+a34b9e9Meanwhile, the clusters are upgrading we can take a look at the multicloud console and see that there is a new policy in enforce mode:
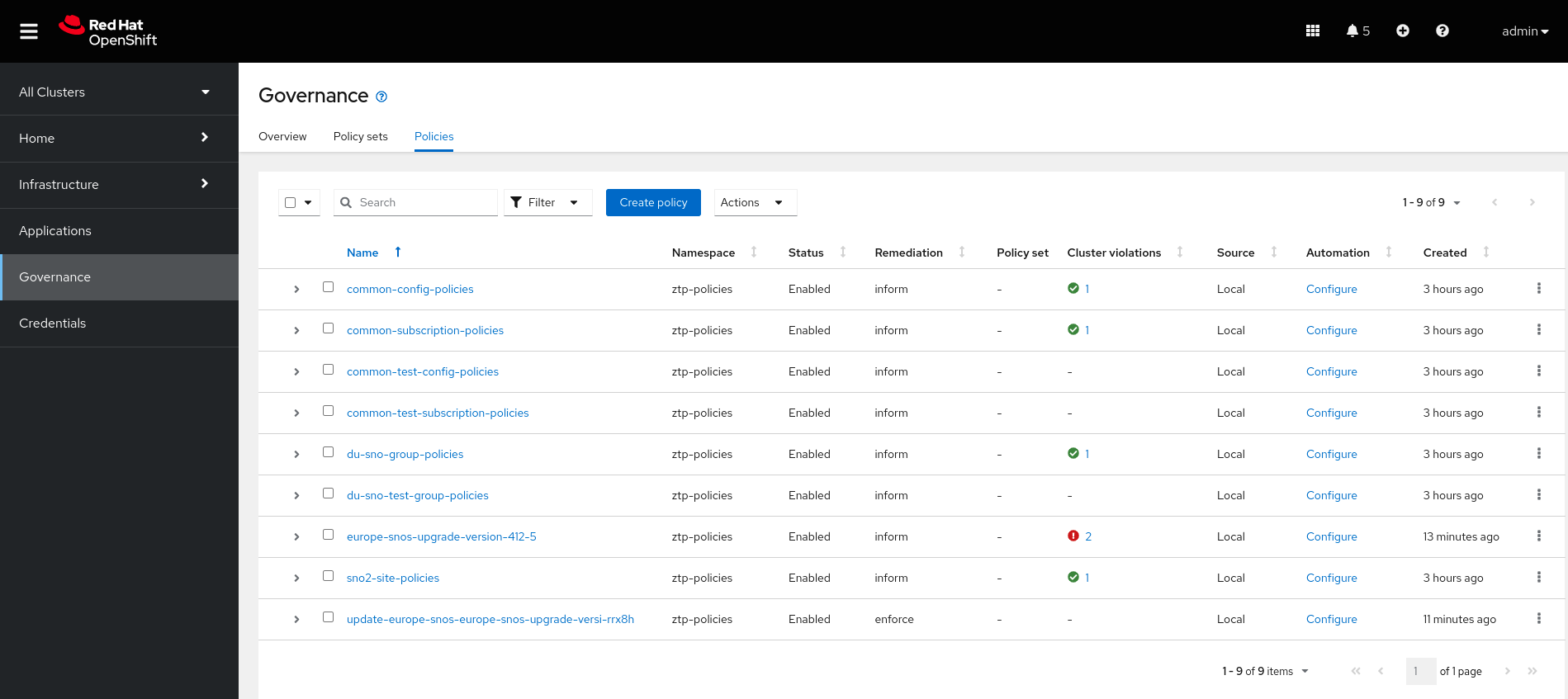
Moving to the Infrastructure → Cluster section of the multicloud console we can also graphically see the upgrading of both clusters:
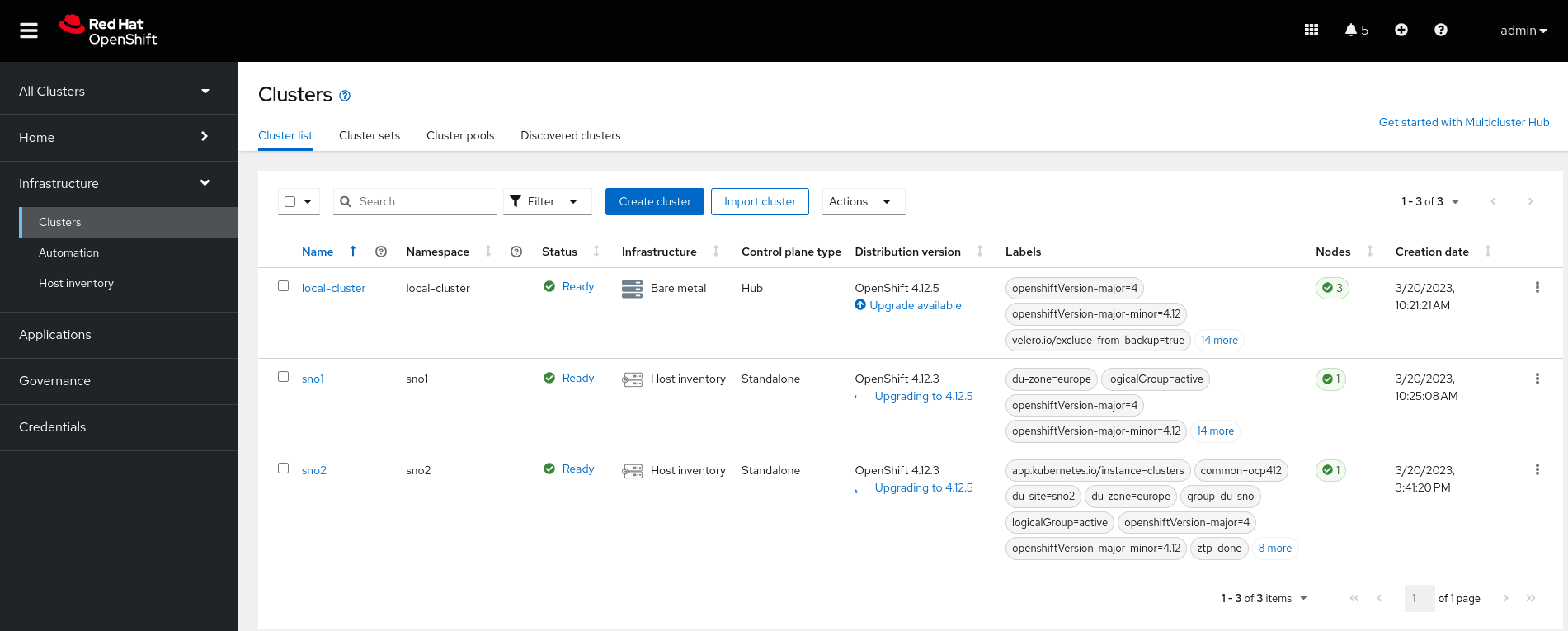
Finally, our clusters are upgraded:
oc --kubeconfig ~/5g-deployment-lab/sno2-kubeconfig get clusterversion,nodesNAME VERSION AVAILABLE PROGRESSING SINCE STATUS
clusterversion.config.openshift.io/version 4.12.5 True False 9m13s Cluster version is 4.12.5
NAME STATUS ROLES AGE VERSION
node/sno2.5g-deployment.lab Ready control-plane,master,worker 5h56m v1.25.4+a34b9e9oc --kubeconfig ~/5g-deployment-lab/sno1-kubeconfig get clusterversion,nodesNAME VERSION AVAILABLE PROGRESSING SINCE STATUS
clusterversion.config.openshift.io/version 4.12.5 True False 33m Cluster version is 4.12.5
NAME STATUS ROLES AGE VERSION
node/openshift-master-0 Ready control-plane,master,worker 18h v1.25.4+a34b9e9Notice that now the upgrade policy europe-snos-upgrade-version-412-5 is now compliant on both clusters. See that, in order to save resources, the enforce policy is removed once the CGU is successfully applied.
And finally, the CGU will be Completed:
oc --kubeconfig ~/5g-deployment-lab/hub-kubeconfig get cgu -ANAMESPACE NAME AGE STATE DETAILS
ztp-install sno2 5h26m Completed All clusters are compliant with all the managed policies
ztp-policies update-europe-snos 106m Completed All clusters are compliant with all the managed policies